For many years we raised the computing power of processors by doubling its transistors, but now that technique is reaching its limits. It was to be expected, doubling the number of transistors on computer chips every 18 months couldn't be sustained forever. When we got at the nano meter scale, weird quantum effects (like quantum tunnelling) started to appear and things got... complicated.
We had a good run. From the 60.000 operations per seconds on the Intel 4004 in the 70's to 15 Trillion operations per second in the new Apple M2 chips today, that was quite a jump, now everybody has a supercomputer in its pocket. Are we over? Apparently not. Actually, we haven't even started.
Sure, we can't double the number of transistors, to squeeze more juice, but there is other ways to get more raw compute power, parallelism, raising the number of cores is the new way forward. Gone are the days were CPU had only one core, today the latest CPU's typically have tens of computing cores, but even they are been outpaced by the latest GPU inside your graphics card with many thousands of cores. The end result is this.
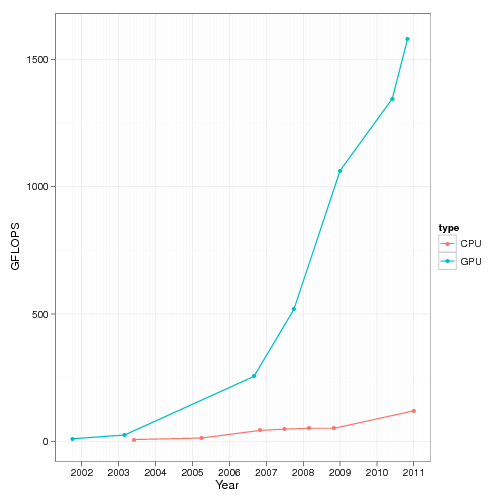
These little beasts have been pushing the limit of computing power, and now, we the enormous demand of compute hungry AI deep learning models, the number of cores will tend to grow exponentially. Can we use it? Sure. Recently, all this compute power was made available to web developers with the latest WebGPU API. This API is an evolution of the old graphics libraries (WebGL) to make this available to generic computing without being explicily tied to graphics but also to get more performance from the GPU.
Take this simple program:
@fragment
fn fragmentMain(@builtin(position) coord: vec4f) -> @location(0) vec4f {
// initial position of the fractal
var p = vec3f( coord.xy / sys.resolution.y, cos(sys.time * .2) + sin(sys.time * .1));
// iterate over the fractal
for (var i = 0; i < 100; i++ ) {
p = (vec3f(1.2,0.999,0.999) * abs( (abs(p) / dot(p,p) - vec3f(1.0 - sys.mouse.y*.1, .9,(sys.mouse.x - .5) * 0.5)) )).xzy;
}
return vec4f(p, 1);
}
It's written in WGSL, an it's a little program that can be runed for every pixel of the screen. If we take that this program can iterates 100 times over a function for every pixel in a 4K monitor with 60 frames per second, that means that the statement inside the loop is executed 50 billion times per second. Or to put it in another way, if we travel at light speed, at every loop, we would only be able to travel 6mm... Not enough to cross the GPU from side to side. And things are going to get even crazier !
Here try it, you can play with your mouse.
